




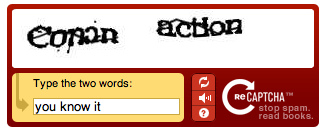
 Znacie to wszyscy – charakterystyczny box z dwoma zniekształconymi słowami. Pod spodem pole na ich przepisanie, aby „udowodnić, że jesteś człowiekiem”. To krótki opis tego, co widzimy gdy korzystamy z reCAPTCHA, zautomatyzowanego testu Turinga, który oprócz odławiania spambotów, wykonuje całkiem pożyteczną pracę.
Znacie to wszyscy – charakterystyczny box z dwoma zniekształconymi słowami. Pod spodem pole na ich przepisanie, aby „udowodnić, że jesteś człowiekiem”. To krótki opis tego, co widzimy gdy korzystamy z reCAPTCHA, zautomatyzowanego testu Turinga, który oprócz odławiania spambotów, wykonuje całkiem pożyteczną pracę.
Zacznijmy od tego, czym jest CAPTCHA. Skrót rozwija się w Completely Automated Public Turing test to tell Computers and Humans Apart – czyli w pełni zautomatyzowany test Turinga pozwalający odróżnić komputery od ludzi. Występuje pod wieloma postaciami, od prostych pytań o wynik działania matematycznego, po absurdalne zadania polegające na policzeniu zwierzątek danego gatunku ukrytych w pofałdowanym tle splątanych linii. Wszystkie mają jedno zadanie – powstrzymać zautomatyzowane programy służące do masowego zamieszczania treści niechcianych przez właścicieli stron internetowych, a więc przede wszystkim spamu.
Szacunki wykonane w 2008 przez zespół z Wydziału Informatyki w Carnegie Mellon University wskazują, że użytkownicy internetu rozwiązywali w tym czasie ponad 100 milionów CAPTCHA każdego dnia. W przeliczeniu daje to setki tysięcy roboczogodzin ludzkiej pracy, poświęconych na rozwiązywanie problemów, z których rozwiązaniem komputery mają problemy. Olbrzymia ilość pracy nie służącej tak naprawdę niczemu.

Wspomniany wyżej zespół postanowił ujarzmić ten potencjał do bardziej pożytecznych celów. Uznali, że CAPTCHA mogą być wykorzystane jako pomoc w digitalizacji materiałów drukowanych. Projekty takie jak Google Books Project, czy Internet Archive wykorzystują oprogramowanie typu OCR (Optical Character Recognition – Optyczne Rozpoznawanie Znaków) do masowego wprowadzania do pamięci komputerów książek i innych tekstów, które powstały przed erą masowej komputeryzacji. Problemem w tym zadaniu jest fakt, że najlepsze oprogramowanie OCR, nie jest w stanie prawidłowo rozpoznać blisko 20% skanowanych słów. Powody tego mogą być różne: niestandardowa czcionka, zanieczyszczenia, defekty wydruku, czy po prostu podział słowa na dwa wiersze. W obliczu ilości skanowanych materiałów ręczne poprawki błędnie rozpoznanych słów to praca z praktycznego punktu widzenia bezsensowna… Chyba, że znajdzie się do jej wykonania miliony ochotników. Widzicie już dokąd to zmierza?
Z jednej strony mamy miliony ludzi, którzy każdego dnia muszą rozpoznać nieczytelne dla komputera litery, by móc skomentować zdjęcia znajomych na ulubionym portalu społecznościowym. Z drugiej zaś mamy miliony zeskanowanych słów, gdzie najlepsze oprogramowanie do automatycznego rozpoznawania tekstu po prostu wymiękło.
Pomysł, gdy się go już pozna, jest trywialny – wyślijmy nierozpoznane słowo do internauty, a on w ramach CAPTCHA rozpozna je za nas.

Jak to działa w praktyce? Proces zaczyna się od przepuszczenia zeskanowanego tekstu przez dwa wysokiej klasy programy OCR. Wyniki ich działania są porównywane i wszystkie słowa, które rozpoznane zostały inaczej przez oba programy, lub które nie znajdują się w słowniku języka angielskiego oznaczane są jako „podejrzane”. Każde takie podejrzane słowo – dalej będziemy nazywać je „słowem nieznanym” – jest następnie umieszczane na obrazku razem z drugim słowem (dalej zwanym „słowem kontrolnym”). Obrazek poddawany jest prostym zniekształceniom i przesyłany do internauty. Dlaczego potrzebne jest słowo kontrolne? Musimy przecież znać odpowiedź na zagadkę, którą wysyłamy do rozwiązania! W tym wypadku zakładamy, że jeżeli otrzymamy poprawne rozwiązanie słowa kontrolnego, to i słowo nieznane zostało wpisane poprawnie.
Aby zmniejszyć skuteczność programów próbujących odgadnąć słowo kontrolne, jest ono pobierane ze słownika ponad 100 000 słów, których nie były w stanie rozpoznać oba wykorzystywane w procesie programy OCR. Z drugiej zaś strony, aby ograniczyć wpływ „dowcipnych” internautów, każde nieznane słowo wysyłane jest do kilku osób i dopiero jeśli odpowiednio duża ilość osób poda takie samo rozwiązanie, uznaje się je za poprawne. Proste, ale czy działa?
Żeby określić skuteczność tego mechanizmu, musimy ocenić dwie rzeczy: po pierwsze z jaką częstotliwością automaty są w stanie obejść test, po drugie jak skuteczni są internauci w odcyfrowywaniu słów.
Jak dotąd nie znalazł się spambot potrafiący obejść reCAPTCHA inaczej, niż przez zgadnięcie słowa kontrolnego, co przy stale rosnącym słowniku tych słów (trafiają tam słowa błędnie rozpoznane przez oba programy OCR, a odcyfrowane identycznie przez trzy pierwsze osoby do których trafiły) daje szanse poniżej 1/100000. Z drugiej zaś strony skuteczność internautów w trafnym rozpoznawaniu słów kształtuje się na poziomie 99,1% (216 błędnie rozpoznanych słów z próbki o liczności 24080), podczas gdy oprogramowanie OCR na tej samej próbce osiągnęło skuteczność rzędu 83,5%. Skuteczność na poziomie 99% dorównuje tej, jaką gwarantują firmy zajmujące się ręcznym przepisywaniem tekstów do komputera. Wrażenie robi też objętość obrobionego tekstu. W 2008 roku, internauci rozpoznawali każdego dnia 4 mln. słów, co odpowiada ok. 160 średniej wielkości książkom!
Gdy więc następnym razem zostaniecie poproszeni o przepisanie dwóch słów, nie zżymajcie się na kilka sekund opóźnienia w surfowaniu, ale przypomnijcie sobie, że właśnie robicie coś pożytecznego.
![]()
von Ahn L, Maurer B, McMillen C, Abraham D, & Blum M (2008). reCAPTCHA: human-based character recognition via Web security measures. Science (New York, N.Y.), 321 (5895), 1465-8 PMID: 18703711





W życiu by mi nie przyszło do głowy, że te słowa to fragmenty książek.
Co więcej, bardzo często przepisuję te słowa z błędami, żeby sprawdzić, czy „złapie” (np. c zamiast e, I zamiast l itp.)
Często łatwo rozpoznać, które słowo jest kontrolne, a które nieznane (skrajny przypadek: jedno ze słów jest napisane cyrylicą albo do góry nogami). Wtedy w miejsce słowa nieznanego można wpisać cokolwiek i mechanizm to zaakceptuje.
Bardzo fajny wpis, a i komentarze podnoszą jego wartość, własnie jestem w trakcie oglądania tego godzinnego filmiku.
Dzięki.
Michale, świetny tekst – witaj na łamach redakcji :-)
Garść dodatkowych informacji: twórca CAPTCHA i reCAPTCHA Luis van Ahn (http://vonahn.blogspot.com) niedawno sprzedał swój wynalazek Google i, co ciekawe, dalej rozwija podwaliny tego rozwiązania – stworzyl serwis Games with a Purpose http://www.gwap.com/gwap/
Szczególnie ciekawy jest jego wyklad dla google, gdzie opowiada o idei gier wykorzystujacyh inteligencję mas do rozwiazywania złożonych problemów http://www.youtube.com/watch?v=qlzM3zcd-lk
Dodam jeszcze, że reCaptcha można także wykorzystywać do ochrony adresów mailowych umieszczanych na stronach www. Na stronie wyświetla się tylko fragment adresu, a żeby poznać cały trzeba przepisać kawałek książki.
http://www.google.com/recaptcha/mailhide/
O mamo. Naprawdę wstawiliście mnie do redakcji :D Muszę się zapoznać z obowiązkami (i co ważniejsze przywilejami XD)
Więcej jest obowiązków ;D
Nasz nowy autor już zyskuje stałych czytelników :)
Badania.net = łowcy talentów ;) Gratuluję Michale świetnego tekstu.
Ciągnie swój do swego ;)
Dziękuję ;)
Świetny tekst i w końcu dowiedziałem się, że w tym słownym szaleństwie, które nieraz doprowadzało mnie do szału, jest sens:)
Rewelacja. Dobrze wiedzieć. Czekam na kolejne teksty Twojego autorstwa.
Skoro czekasz, muszę dostarczyć. Dzięki za motywację ;)